Bikash Pandey
Passionate about providing scalable and robust solutions from data while learning and establishing new concepts. Regular attendee of hackathons and meetups. Open source Contributor.
I like to work on web technologies with a special knack of AI. Open to Collaborations on interesting projects. I sometimes try to document my projects on youtube, feel free to drop by or hit me up with some ideas. Most of my projects are based on real life solutions which leverage these technologies.
View My LinkedIn Profile
Visit me on Youtube
Youtube App
Project Goal
To make a System that fetches recently uploaded videos (related to a fixed keyword) and exposes the videos for search in reverse chronological order of their publishing date-time from YouTube for a given tag/search query in a paginated response.Github
Here’s an Architechure diagram of the application
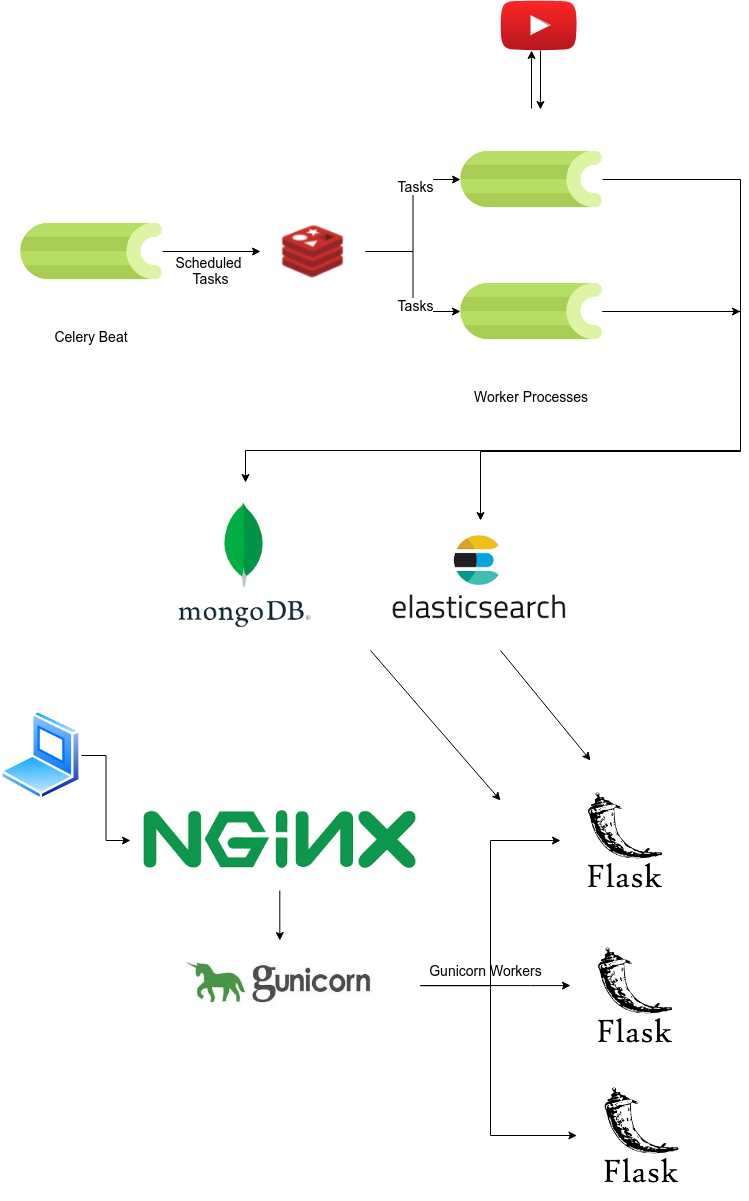
Basic Specifications:
-
We should have a background schedular running at an interval (of say 10 seconds) for fetching the latest videos for a predefined search query and should store the data of videos in a database with proper indexes.
-
A GET API which returns the stored video data in a paginated response sorted in descending order os published datetime.
-
A basic search API to search the stored videos using their title and description in paginated fashion.
-
Dockerize the Project. (preferably docker compose to include redis and elaticsearch)
-
It should be scalable and optimized.
Folder Structure
.
├── Dockerfile
├── myapp
│ ├── celery_schedular.py
│ ├── celery_worker.py
│ ├── config
│ │ ├── __base.py
│ │ ├── __dev.py
| | ├── .env (secret)
│ │ ├── __init__.py
│ │ └── __prod.py
│ ├── source
│ │ ├── celery_config.py
│ │ ├── cli.py
│ │ ├── es_ops.py
│ │ ├── __init__.py
│ │ ├── models.py
│ │ ├── search
│ │ │ ├── __init__.py
│ │ │ └── routes.py
│ │ └── tasks.py
│ └── wsgi.py
├── README.md
├── requirements.txt
├── supervisord.conf
├── tests
│ ├── __init__.py
│ ├── test_basic.py
│ └── test_search.py
└── yt-app-arch.png
Installing Requirements
Using a virtualenv is preferred
- Python and pip (requirements.txt)
- Redis
- ElasticSearch
- MongoDB
Youtube Fetch Schedular
This module does the following jobs:
1. Fetch youtube data for a fixed search query (every 4 minutes)
2. Saves the youtube data in database
Start Redis
1. `redis-cli shutdown`
2. `redis-server`
Start Elastic search
./bin/elasticsearch
Start celery-beat (schedular)
`celery beat -A myapp.celery_schedular --loglevel=INFO`
Start celery-worker
In Windows: `celery worker -A myapp.celery_worker.celery -P solo --loglevel=INFO`
In UNIX : `celery worker -A myapp.celery_worker.celery --loglevel=INFO`
Youtube Search api
This module provides api for performing search on the youtube data
To run the Flask server
Development server
set FLASK_APP=myapp.wsgi.py (linux : export FLASK_APP=myapp.wsgi.py)
flask run -h 0.0.0.0 -p 8091
Production server
gunicorn --workers=2 myapp.wsgi:app -b localhost:8091
Docker commands
docker build --tag youtube-app .
docker run -d -p 8091:8091 --net="host" youtube-app
Improvements TODO- (9 June 2021)
-
Databases - We are using two different databases here, Mongodb and Elasticsearch (which is a search engine), but in our case we can resort to using only elasticsearch. Also there will be data inconsistency if we have two sources of truths, synchronizing data in two different kind of databases is a scenario we might not want to have.
-
Tests - We have incomplete tests as I write this, completing the tests would be nice.
-
Pagination - The pagination for the search APIS has been implemented using
offsetandlimitin databases and the sorting of the data based on the publised date. The logic looks something like thisYoutube.objects.order_by('-published_at').skip( offset ).limit( size ). The problem with this approach is that it tries to sort the entire data first and then goes to an offset from which it tries to limit. Instead of this we can try to index the published_at date so that the sorting happens faster, also instead of offset we should try out cursor indexing where we directly go to the published_at time and limit from that point. (all of this can be acheived by indexing on published_at) -
Currently inorder to paginate on Elasticsearch we are using
sizeandfromkeywords, which also kind of feels like offset. Instead we should try outscrollwhich fixes the data snapshot for certain time and on which we can paginate however we like. -
Points 3 and 4 unknowingly tries to address a major UX issue which happens in the current version because the schedular continously pools data in the background while the user makes searches and paginates over the result. What might happen is that while the user is on the page 3 or 4 of a search result when he/she comes back to page 1 will see entirely new results.
-
In the following code sample link
for data in response['items']: data['video_id'] = data['id']['videoId'] data['published_at'] = datetime.datetime.fromisoformat(data['snippet']['publishedAt'][:-1]) del data['id'] try: Youtube(**data).save() except NotUniqueError: continue doc_to_insert = { "title": data['snippet']['title'], "description": data['snippet']['description'], } insert_index(id=str(data['video_id']), data=doc_to_insert) print(doc_to_insert)once we have a default number of links from the youtube api we loop through each of the data and save it one at a time. We should try to save it one at a time.